Raking¶
rake¶
L’istruzione rake genera delle variabili di ponderazione dei dati in base alle distribuzioni marginali attraverso un algoritmo di Iterative Proportional Fitting (IPF).
Argomenti:
- title: il titolo della ponderazione (opzionale)
- :names => varnames: la lista dei nomi delle variabili di ponderazione che devono essere create: la variabile di ponderazione con media 1, più eventuali altre variabili di espansione (default: ipf)
- :counts: la lista delle numerosità totali dei casi delle variabili di espansione.
- :population: un hash con i marginali delle variabili di ponderazione, nel formato: nome_var => [marginali]. I valori vengono interpretati come proporzioni. Le variabili non devono avere casi mancanti. Il numero di marginali di ciascuna variabile deve corrispondere al numero di livelli della variabile
- :aggr => {var1 => {[codes] => cod1, [codes] => cod2}, var2...}: un hash con i codici da aggregare di una o più variabili. Permette di aggregare i livelli delle varabili e considerarli come un’unica classe, aggregando sia i dati che i valori in population. Utile sia se non si vuole creare la variabile ricodificata, sia in caso di basse o nulle numerosità in una classe.
- :pw => varname: il nome della variabile peso di partenza.
- :if_na: comportamento in caso di valori mancanti nelle variabili di ponderazione:
- :error: (il default) interrompe l’esecuzione
- :na: assegna peso uguale a NA (valore mancante)
- valore: assegna peso uguale a valore
- :if_zero: comportamento in caso di un codice presente in population, ma senza nessun caso nel sample:
- :error: (il default) genera un errore
- :skip: continua l’esecuzione ignorando il codice
- :if => expression: filtro per selezionare un sottoinsieme di casi da ponderare [1]. Ha il sopravvento rispetto a un eventuale filtro impostato con l’istruzione filter (altrimenti viene lasciato il valore preesistente o NA se la variabile di ponderazione non esiste già)
- :xlsx => filename: esporta le variabili di ponderazione create in un file Excel 2007
- :sav => filename: esporta le variabili di ponderazione create in un file SPSS
- :id => varname: specifica l’identificativo dei record da utilizzare nel file di esportazione. I dati saranno ordinati sull’id
- :maxit => number: controlla il numero di iterazioni (default: 100)
- :delta => number: il modello converge quando la differenza massima in valore assoluto tra le percentuali dei marginali ottenuti e di quelli desiderati è inferiore o uguale a delta (default: 0.01)
- :epsilon => number: il modello converge quando la differenza del valore massimo in valore assoluto dei pesi tra le ultime due iterazioni è inferiore o uguale a epsilon
- :print => :iter: stampa un riepilogo delle iterazioni
- :save => false|true: genera un file XLSX con il report della ponderazione (default true)
- :path => path: il perrcorso per i file di output (default la cartella di lavoro)
- :label => "string": (opzionale) l’etichetta da assegnare alle variabili peso
- :ndec => number: imposta il numero di decimali del formato e dei valori delle variabili peso (default il numero massimo trovato nei valori calcolati)
- :size => number: imposta il numero di interi del formato delle variabili peso. Non ha effetto sui valori effettivamente calcolati. (default il numero massimo trovato nei valori calcolati)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # genera solo il peso per la ponderazione
rake :names => :peso,
:population => { :sesso => [150, 150], :eta => [25, 75, 150, 50] },
:xlsx => "ipf", :id => :ser_no
# genera 3 variabili di ponderazione
rake "Ponderazione con socio-demo",
:names => [:ipf, :espcam, :espuni],
:counts => [350, 4500],
:population => { :sesso => [150, 150],
:eta => {1=>25, 2=>75, 3=>150, 4=>0},
:area => {1=>75, 2=>75, 3=>75, 4=>75} },
:sav => "ipf", :id => :ser_no
# pondera in due step i dati
rake :names => :ipf, ... :if => {:campio => 1}
rake :names => :ipf, ... :if => {:campio => 2}
# considera le classi 1 e 2 di eta come un'unica classe aggregando populatio e i dati
rake :names => :w1,
:population => { :sesso => {1=>52, 2=>48},
:eta => {1=>15.3, 2=>28.7, 3=>38.7, 4=>17.3},
:area => {1=>31.0, 2=>16.7, 3=>23.3, 4=>29.0},
},
:aggr => { :eta => {[1,2] => 2} }
# aggr funziona anche se in population i dato è già aggrgato
rake :names => :w1,
:population => { :sesso => {1=>52, 2=>48},
:eta => {2=>44, 3=>38.7, 4=>17.3},
:area => {1=>31.0, 2=>16.7, 3=>23.3, 4=>29.0},
},
:aggr => { :eta => {[1,2] => 2} }
|
Casi particolari:
- Se sono presenti codici in più nella variabile rispetto a population, viene generato un errore
- Se sono presenti codici in più in population rispetto alla variabile, vedere il parametro if_zero
- Se una variabile presenta valori mancanti, vedere il parametro if_na
- Se presenti codici senza etichetta, viene generato un warning (!)
- Se sono presenti codici in population con valore zero, ma con osservazioni diverse da zero, viene generato un warning (!)
- Se sono presenti codici in population con valore zero e senza osservazioni, viene generato un warning (!)
- Se nella variabile sono presenti livelli senza osservazioni che non sono presenti in population, viene generato un warning (!)
Output¶
rake genera alcune tabelle di diagnostica nella finestra di log e in un file in formato xlsx (rake-title.xlsx).
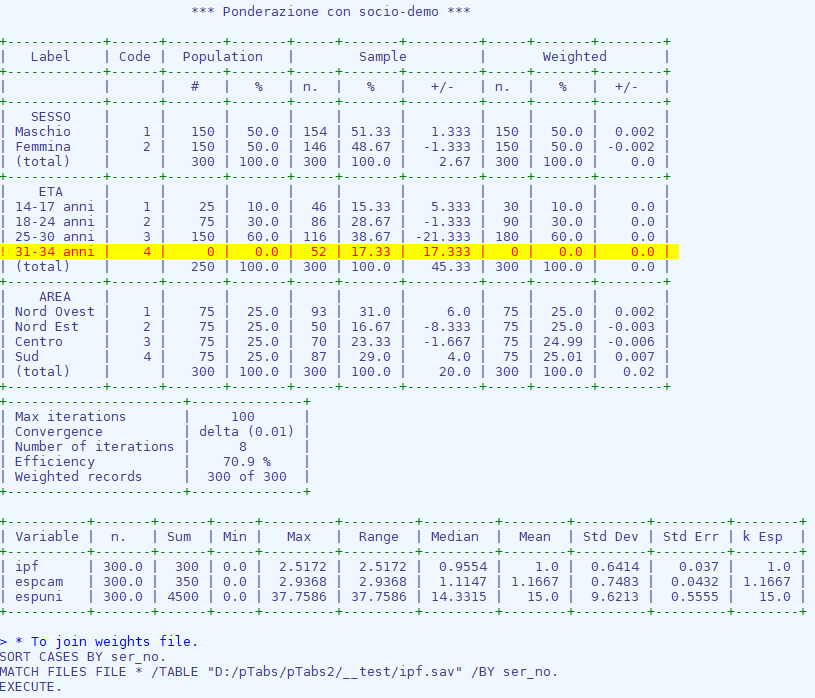
population¶
- i valori marginali possono essere inseriti come hash, indicando il codice e il rispettivo valore
- i valori marginali possono essere inseriti come vettore e in tal caso i valori verranno attribuiti a una sequenza di codici a partire da 1
- oltre a un solo codice è possibile specificare anche un vettore di codici oppure un range di valori per attribuire lo stesso marginale a più di un codice
- :else al posto del codice indica che il valore deve essere attribuito a tutti i codici non specificati
- :sample al posto del valore indica che deve essere mantenuta la percentuale effettivamente riscontratta nel sample di dati
- :prop al posto del valore indica che la quota residuale rispetto ai valori indicati deve essere ripartita in base alle proporzioni esistenti nel sample. Il totale di riferimento viene calcolato in base alla somma dei valori inseriti per gli altri codici: 1, se la somma è minore di 1; 100 se la somma è minore di 100; il numero di casi se la somma è maggiore di 100.
1 2 3 4 5 6 7 8 9 10 | :v1 => [50, 25, 25, 20] # un vettore di valori
:v1 => {1=>50, 2=>25, 3=>25, 4=>20} # un hash con le coppie codice / valore
:v1 => {1=>50, 2=>25, 3=>25, 4=>:sample} # il codice 4 utilizza la percentuale esistente nel sample
:v1 => {1=>50, 2=>:sample, 3=>25, 4=>:sample} # :sample per i valori 2 e 4
:v1 => {1=>50, 3=>25, [2,4]=>:sample} # :sample per i valori 2 e 4
:v1 => {1=>50, 2=>50, 3..4=>:sample} # :sample per i valori 3 e 4
:v1 => {1=>50, 2=>50, :else=>:sample} # :sample per i valori non ancora specificati (3 e 4)
:v1 => :sample # :sample per tutti i valori della variabile
:v1 => {2=>25, 3=>35, :else=>:prop} # la quota rimanente (40%) viene ripartita sui codici 1 e 2 in base alle proporzioni esistenti nel sample
:v1 => {1=>20, 2=>25, 3=>:prop, 4=>20} # al codice 3 viene attribuio il totale della quota rimanente (35%)
|
rake_stop_on_failure¶
Il parametro di configurazione rake_stop_on_failure determina il comportamento in caso di non convergenza:
- true: errore (default)
- false: continua con un warning ma genera comunque le variabili di ponderazione
Consiglio
Per l’utilizzo delle variabili di ponderazione si veda Ponderazione.
Valori di ritorno¶
rake restituisce un oggetto contenente le statistiche della ponderazione,
che, se assegnato a una variabile, può essere utilizzato nello script per condizionarne l’esecuzione.
Se non si assegna esplicitamente rake a una variabile, è possibile usare la variabile $rk che contiene un riferimento all’ultima istruzione rake eseguita.
L’oggetto disponde dei metodi .efficiency, .niter, .n, .sum, .min, .max, .range , .median, .mean, .stdev, .serr, .esp che restituiscono le statistiche relative alla prima variabile di ponderazione. E’ inoltre possibile accedere alle statistiche delle altre variabili di ponderazione con la sintassi variabile["nome_peso"]: per es. result["ipf2"].esp
Il metodo .filename restituisce il nome del file XLSX del report della ponderazione.
Il metodo .info restituisce un hash con le statistiche della ponderazione.
Il metodo .info_table "title" genera nel report una tabella con le statistiche della ponderazione.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | ### rilanciare una nuova ponderazione
# prima ponderazione
result = rake :names ...
if result.min < 0.3 || result.max > 3
# nuova ponderazione, con meno variabili marginali o con classi più aggregate
result = rake :names ...
end
# se i valori non sono ancora soddisfacenti
err "i valori dei pesi sono troppo alti: #{result.min} <> #{result.max}" if result.min < 0.3 || result.max > 3
### una scelta tra due ponderazioni in base all'efficienza
if res1.efficiency > res2.efficiency
weight! :peso1 => :peso
else
copy :peso2 => :peso
end
# oppure
if res1.efficiency > res2.efficiency
copy :peso1 => :peso
else
copy :peso2 => :peso
end
weight! :peso
### mostra una finestra di dialogo se l'efficienza è minore di 70
# utilizzando la variabile $rk
stop unless ask("L'efficienza è #{$rk.efficiency.round(2)}. Continuo comunque?") if $rk.efficiency < 70
|
La variabile $rks contiene i risultati di tutte le istruzione rake eseguite nello script.
$rks.filenames restituisce i nomi dei file XLSX dei report delle ponderazioni generati.
$rks.info_table "title" genera nel report una tabella con le statistiche di tutte le ponderazioni eseguite.
1 2 3 4 5 6 7 8 | # unisce i report di più ponderazioni generate nello script
xlsx.join($rks.filenames).save("report_ponderazioni")
# generara un report con le statistiche riassuntive di tutte le ponderazioni eseguite
$rks.info_table "Ponderazioni"
xlsx_index_
render :xlsx
|
xlsx.weights¶
xlsx.weights legge un file XLSX contenente i marginali per la ponderazione. I marginali possono essere organizzati in più fogli. Un foglio può contenere più gruppi di marginali identificati dalla colonna weight. I marginali possono essere successivamente utilizzati nell’istruzione rake attraverso l’identificativo indicato nella colonna weight.
Esempio di formato del foglio dei pesi:
| weight | var | code | value |
|---|---|---|---|
| peso1 | sex | 1 | 51,3 |
| 2 | 48,7 | ||
| age | 1 | 23,9 | |
| 2 | 32,8 | ||
| 3 | 43,3 | ||
| peso2 | sex | 1 | 50 |
| 2 | 50 | ||
| age | 1 | 50 | |
| 2 | 25 | ||
| 3 | 25 | ||
| area | 1 | 20 | |
| 2 | 80 |
Queste quattro colonne sono obbligatorie e devono avere le intestazioni indicate. E’ comunque possibile inserire uteriori colonne, in qualsiasi posizione, contenenti label, annotazioni, ecc.
Inoltre è possibile inserire una colonna con intestazione skip. Se viene inserito qualsiasi valore in questa colonna in corrispondenza del nome della variabile, la variabile verrà esclusa dalla ponderazione.
E’ possibile generare una bozza del file con rake :build.
Argomenti:
- filename: il nome del file XLSX
- :sheet => name: il nome del foglio (default il primo foglio)
- :pct => false|true: ripercentualizza i marginali (se indicati in modo esplicito per ciascun codice; default false)
- :ndec => 1: numero di decimali per la percentualizzazione (default 1)
- :skip => false|true: true esclude le variabili con un valore nella colonna skip (default); false ignora la colonna skip
- :quiet => false|true: true non stampa nel log i pesi trovati; false (default) stampa i pesi (default)
1 2 3 | wgts = xlsx.weights "pesi", :sheet => "Foglio1"
rake :names => :ipf, :population => wgts.peso2
|
E’ possibile estrarre solo alcune variabili dai pesi:
1 2 | rake :names => :ipf, :population => wgts.peso2(:gender, :mcr)
rake :names => :ipf, :population => wgts[:peso2, :gender, :mcr]
|
rake :build¶
Calcola i marginali per la ponderazione utilizzando le distribuzioni presenti nel dataset. L’istruzione di ponderazione viene stampata nel log così che può essere copiata e modificata. Inoltre viene restituito un oggetto che può essere successivamente utilizzato per eseguire la ponderazione su altri dataset, generare un file YAML con i marginali per ptLab o generare un file XLSX da utilizzare con l’istruzione xlsx.weights.
Argomenti:
- :build => varlist: l’elenco delle variabili
- :ndec => n: il numero di decimali a cui arrotondare i marginali (default 1)
- :name, :xlsx, :sav e :id, se inseriti, verranno riportati nell’istruzione rake
Metodi dell’oggetto restituito:
- .execute: esegue l’istruzione di ponderazione
- .population: restituisce un hash con i marginali delle variabili. Può essere usato nel parametro :population di rake
- .variables: restituisce un array con l’elenco delle variabili
- .to_x(filename): genera un file XLSX. Oltre alle percentuali dei marginali, il file contiene i valori assoluti, le basi e le etichette. Può essere utilizzato dall’istruzione xlsx.weights
- .to_y(filename): genera un file YAML per ptLab
1 | rake :build => [:sesso, :eta, :titolo]
|
1 2 3 4 | builder = rake :build => [:sesso, :eta, :titolo], :ndec => 2, :name => :peso
p builder.variables
builder.to_y "pop3"
builder.to_x "pop3"
|
1 2 3 4 5 6 7 8 9 | builder = rake :build => [:sesso, :eta, :titolo], :name => :peso, :sav => "peso1", :id => :ser_no
spss.open "otherfile1"
rake :names => :peso,
:population => builder.population,
:xlsx => "ipf", :id => :ser_no
spss.open "otherfile2"
builder.execute
|
1 2 3 4 5 6 | builder = rake :build => [:sesso, :eta, :titolo], :ndec => 2, :name => :peso1
builder.to_x "pop3"
pesi = xlsx.weights("pop3", :pct => true, :ndec => 1)
rake :names => :peso,
:population => pesi.peso1,
:xlsx => "ipf", :id => :ser_no
|
Note
| [1] | Per le espressioni vedi anche Espressioni |