Operazioni sui dataset¶
Workspace¶
E’ possibile caricare più di un file di dati, allo scopo, per esempio, di alternare la fonte di dati delle tavole. Inoltre alcuni comandi generano o richiedono un ulteriore dataset. In tali casi, i dati devono essere assegnati a un’area di lavoro differente (workspace), utilizzando il parametro :ws => :name, dove :name è un simbolo. pTabs2 utilizza invece automaticamente dei numero progressivi come identificativo del workspace. Il workspace di default è 0.
1 2 3 4 | spss.open "dati" # carica i dati nel workspace 0
spss.open "altri_dati", :ws => :ds2 # carica i dati nel workspace :ds2
xlsx.open "altri_dati", :ws => :xdata # carica i dati nel workspace :xdata
xlsx.open "altri_dati", :ws => :xdata2, :bk => true # carica i dati nel workspace :xdata2 senza attivarlo
|
ws¶
ws :name attiva un dataset differente e lo rende disponibile per l’elaborazione.
ws.rename¶
ws.rename :newname rinomina il dataset attivo come :newname.
ws.close¶
ws.close :name chiude il dataset indicato o quello attivo, se non specificato il nome.
ws.close_all¶
ws.close_all chiude tutti i dataset.
ws.new¶
ws.new :name crea un nuovo workspace con un dataset vuoto.
ws.copy¶
ws.copy :name, [all: true|false, activate: true|false, keep:|drop:] fa una copia del dataset attivo nel workspace :name.
- :all => true|false copia tutti i dati anche se attivo un filtro (default true)
- :activate => true|false attiva il nuovo dataset (default false)
- :keep => varlist elenco delle variabili da copiare (default tutte)
- :drop => varlist elenco delle variabili da eliminare (default nessuna)
ws.exist?¶
ws.exist?(:name) restituisce true se il dataset :name esiste e false se non esiste.
ws?¶
ws? elenca i dataset esistenti.
> Datasets:
+---+--------+------+------+--------+---------+----------+---------+----------------+
| # | active | ws | name | fields | records | filtered | filter | filter caption |
+---+--------+------+------+--------+---------+----------+---------+----------------+
| 1 | * | 0 | | 97 | 300 | | | |
| 2 | | stk1 | | 3 | 600 | 72 | cell=10 | Base: Cell 10 |
| 3 | | stk2 | | 4 | 13800 | | | |
+---+--------+------+------+--------+---------+----------+---------+----------------+
ws.list¶
ws.list restituisce l’elenco (array) dei simboli dei nomi dei dataset.
1 2 3 4 5 6 7 8 | # unisce tra loro i workspace
ws.list.each_with_index do |name, index|
if index == 0
ws name
else
union name, :mode => :union
end
end
|
n¶
n seleziona le osservazioni indicate. Gli indici si intendono a base 1.
- n: seleziona le prime n osservazioni
- -n: seleziona le ultime n osservazioni
- n1..n2: seleziona le osservazioni nel range indicato
- [n1,n2,n3,n#]: seleziona le osservazioni con gli indici indicati
- 0.n: la proporzione di casi da selezionare
- :step => n: seleziona un record ogni n
- :start => n: il record da cui partire quando indicato :step
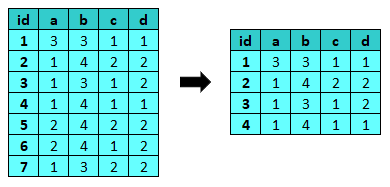
1 2 3 4 5 6 7 8 | n 100
n -10
n 30..75
n [1, 5, 231, 9, 10]
n [100]
n 0.20
n :step => 2
n :step => 3, :start => 2
|
sample¶
sample estrae un sample delle osservazioni.
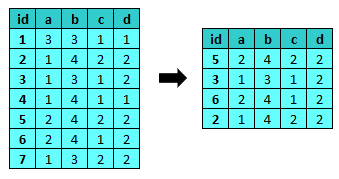
Se viene specificato il nome di una variabile e un valore i casi casi estratti vengono solo marcati, altrimenti i casi non estratti vengono esclusi dal dataset. Se è attivo un filtro le osservazioni vengono estratte tra i casi attivi.
Parametri:
- il numero di osservazioni da estrarre o, se indicato un numero decimale tra 0 e 1, la proporzione di casi da estrarre
- :varname => {code1 => N, code2 => N}: le probabilità di estrazione rispetto a una variabile
- :flag => :varname | [:varname, value] | {:varname => value}: il nome eo il valore di una variabile per identificare i casi estratti
- :seed => number: un seed per replicare i risultati
- :repeat => true|false: estrazione con riposizionamento (default false). Permette anche di estrarre un numero di record superiore ai record disponibili
- :view => false|true|varlist: (default false) true non elimina nessun caso dal dataset attivo, ma restituisce una view contenente i dati estratti, accessibile attraverso i metodi illustrati in File di dati #get. varlist limita la view alle sole variabili elencate. Se la lista è di una sola variabile, restiduisce semplicemente un array con i valori della variabile.
- :if => expr: filtro per selezionare un sottoinsieme di casi (Espressioni). Prevale su un eventuale filtro impostato sul dataset
- :ws => :name: crea un nuovo workspace con i dati estratti lasciando invariato il dataset attivo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | sample 100
sample 0.3
sample 100, :genere => {1 => 30, 2 => 70}
sample 100, :genere => {1 => 30, 2 => 70}, :flag => [:sample, 1]
filter "!sample"
sample 100, :genere => {1 => 30, 2 => 70}, flag: {:sample => 2}
all
data = sample(10, :view => true)
value_if :v1, 3, :respnum => data[:respnum]
value_if :v1, 3, :respnum => sample(10, :view => :respnum)
|
ttsplit¶
ttsplit crea una variabile che suddivide le osservazioni in due set: training set e test set (o validation set o hold-out set).

Parametri:
- varname: il nome della variabile che identifica i due set di dati
- n: il numero o la proporzione di osservazioni da assegnare al training set
- :seed => number: un seed per replicare i risultati
1 2 3 | ttsplit :tvset, 200
ttsplit :tvset, 0.7
|
kfold¶
kfold crea una variabile che suddivide le osservazioni in k set di dati (k-Folds) delle stesse dimensioni.
Parametri:
- varname: il nome della variabile che identifica i set di dati
- k: il numero di gruppi (folds) di osservazioni in cui dividere i dati o la proporzione di casi che deve contenere ciascun gruppo
- :seed => number: un seed per replicare i risultati
1 2 3 | kfold :folds, 10
kfold :folds, 0.20
|
divide¶

divide suddivide i record del dataset attivo in nuovi workspace, uno per ciascun codice delle variabili elencate.
Parametri:
- varlist: il nome di una variabile o un elenco di variabili
- :interaction => true|false: false tratta le variabili separatamente; true considera le combinazioni delle variabili (default false)
- :keep => varlist: elenco delle variabili da copiare (default tutte)
- :drop => varlist: elenco delle variabili da eliminare (default nessuna)
Restituisce l’elenco dei nomi dei workspace generati.
Un eventuale filtro attivo verrà disattivato.
La variante divide! chiude il dataset attivo.
1 2 3 | divide :sample
divide :gender, :area
|
expand_grid¶
expand_grid genera un dataset con le combinazioni dei livelli delle variabili o dei valori forniti.
Il workspace deve essere vuoto, pertanto expand_grid deve essere eseguito prima dell’apertura di un file di dati, oppure è possibile utilizzare le isrtruzioni ws.close o ws.new.

Parametri:
- varlist: la lista delle variabili. Se non esistono è necessario specificare anche il parametro :values.
- :values: un array con gli array o i range dei codici di ciascuna variabile. Se non specificato, utilizza i livelli delle variabili.
1 | expand_grid :a, :b, :c, :values => [1..2, 1..3, 0..1]
|
1 2 3 4 5 | new :sex, :sng, 1, :label => "Genere", :levels => ["M", "F"]
new :mcr, :sng, 1, :label => "Macroarea", :levels => ["NO", "NE", "C", "S"]
new :age, :sng, 1, :label => "Età", :levels => ["18-30", "31-40", "41-50", "51-60", "60+"]
expand_grid :sex, :mcr, :age
|
1 2 3 4 | expand_grid :sex, :mcr, :age, :values => [[2], 2..4, [1,3..5]]
ws.close
expand_grid :sex, :mcr, :age, :values => [1..2, 1..4, 1..5]
|
1 2 3 4 | spss.open "demo_data"
rec_id = f(:ser_no).data
ws.close
expand_grid :rec_id, :month, :values => [rec_id, 1..12]
|
1 | expand_grid :rec_id, :month, :values => [1..1000, 1..12]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | attrib = {
:seat => ["6", "7", "8"],
:cargo => ["2ft", "3ft"],
:eng => ["gas", "hyb", "elec"],
:prince => ["30", "35", "40"]
}
# come variabili stringa
expand_grid attrib.keys, :values => attrib.values
# come variabili numeriche con etichette
attrib.each do |name, levels|
new name, :sng, 1, :levels => levels
end
expand_grid attrib.keys
|
shuffle¶
shuffle riordina casualmente i record del dataset.
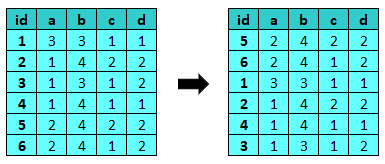
Parametri:
- number un seed per replicare i risultati
1 | shuffle
|
sort¶
sort riordina i record del dataset rispetto alle variabili date.
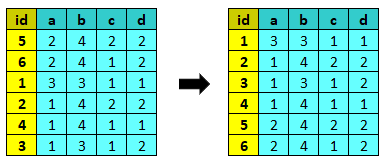
Parametri:
- var|varlist: la variabile o la lista di variabili su cui ordinare i dati
- var => :a|:d|[]: la variabile e il simbolo per la direzione dell’ordinamento (:a|:d) o un vettore con i valori rispetto ai quali ordinare i dati
- [var, :a|:d|[]]: la variabile e il simbolo per la direzione dell’ordinamento (:a|:d) o un vettore con i valori rispetto ai quali ordinare i dati
1 2 3 4 5 6 7 8 9 | sort :ser_no
sort :cognome, [:eta, :d]
sort :prof, [:genere, :d], :name
sort :prof => :a, :genere => :d, :name => :a
sort :area => ["NO", "NE", "C", "S"], :recid => :a
sort :area => %w(NO NE C S), :recid => :a
|
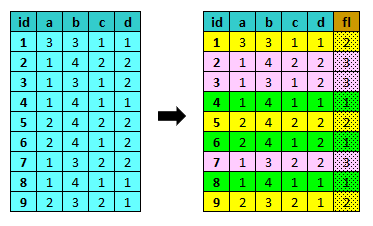
ddup¶
ddup identifica ed elimina i record duplicati.
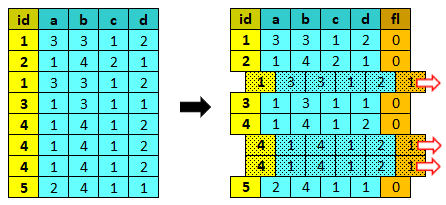
E’ possibile indicare le variabili su cui effettuare il controllo dei record duplicati oppure utilizzare tutte le variabili.
Parametri:
- varlist: variabili su cui effettuare il controllo
- :show => true|false: visualizza il report con i casi duplicati: true|false, default true
- :drop => true|false: elimina i record duplicati: true|false, default true
- :flag => :varname | [:varname, value] | {:varname => value}: il nome eo il valore di una variabile per identificare i casi duplicati
- :id => :varname: il nome di una variabile per identificare i gruppi di casi duplicati
- :prog => :varname | [:varname, start_value] | {:varname => start_value}: il nome di una variabile in cui inserire un progressivo dei record doppi. start_value è il valore da cui pardire: default 0.
- :first => true|false: tiene il primo record tra quelli duplicati e elimina gli altri: true|false, default true
- :last => true|false: tiene l’ultimo record tra quelli duplicati e elimina gli altri: true|false, default false
- :info => [varlist]: aggiunge ulteriori variabili da visualizzare nel report: [varlist]
- :labels => true|false: stampa le etichette accanto ai valori (default false)
- :xlsx => filename: nome del file xlsx (senza estensione) in cui salvare la tabella
1 2 3 4 5 6 7 8 9 10 11 12 13 | # elimina i record che risultano doppi rispetto a tutte le variabili
ddup
# elimina i record che risultano doppi per le variabili id_fam e id_pers; tiene l'ultimo record
ddup :id_fam, :id_pers, :last => true
# non elimina i record, produce solo il report aggiungendo delle variabili
ddup :ser_no, :drop => false, :info => [:genere, :area, :name]
# numera i record doppi e poi genera un nuovo id univoco
ddup :ser_no, :prog => [:ndup, 1]
fillval :ndup, 0
compute :newid => "ser_no*10+ndup"
|
ddup :ser_no, :info => [:etaq, :area, :name]
+ sono stati trovati ed eliminati 12 record duplicati
+----+--------+------+------+----------------------+-------+-----------+
| # | ser_no | etaq | area | name | [dup] | [deleted] |
+----+--------+------+------+----------------------+-------+-----------+
| 1 | 1 | 25 | 1 | SKWAJUI ILOGWDPIVA | 1 | |
| 2 | 1 | 30 | 1 | XMZXPE ILEWGYS | - | * |
| 3 | 2 | 24 | 1 | GSSDMV HJLOYTEY | 2 | |
| 4 | 2 | 15 | 1 | JNXFDWSOEJH JPVQCF | - | * |
| 5 | 3 | 15 | 1 | JCZOYHSFBZN FBVREQHH | 3 | |
| 6 | 3 | 31 | 1 | IZOQJYGAX ALSVOXA | - | * |
| 33 | 3 | 25 | 1 | FQZASOTDJ UQYRGKRR | - | * |
| 45 | 3 | 28 | 1 | BLVLLEBCKBP FKMISPF | - | * |
| 7 | 4 | 31 | 1 | | 4 | |
| 8 | 4 | 25 | 1 | OFYWVGC DUCYDMQIASW | - | * |
| 9 | 5 | 34 | 1 | EBCQROL ASZCUE | 5 | |
| 10 | 5 | 30 | 1 | TXZYWQNQMEMT RYWJNSG | - | * |
| 11 | 6 | 25 | 1 | BYYLTW AFALISHXHJ | 6 | |
| 12 | 6 | 33 | 1 | RYYEYFT DSYWOWZ | - | * |
| 13 | 7 | 25 | 1 | LLCPEFINVD TTUFESW | 7 | |
| 14 | 7 | 30 | 1 | KDGJNB IXHKKYBU | - | * |
| 15 | 8 | 20 | 1 | WFIOQXFL GJNMZCWNZW | 8 | |
| 16 | 8 | 25 | 1 | KTFKDRCEQXMP NREDCXC | - | * |
| 17 | 9 | 24 | 1 | GOMSFQWZPFBI VJBKNUQ | 9 | |
| 18 | 9 | 25 | 1 | USEFPLYQT OOPXIVWE | - | * |
| 19 | 10 | 27 | 1 | DQLLOWOO QZCQXWG | 10 | |
| 20 | 10 | 32 | 1 | RZXBOAASXJ FCQORRS | - | * |
+----+--------+------+------+----------------------+-------+-----------+
union¶
union unisce i casi di un dataset al dataset attivo.
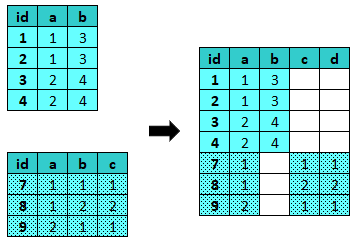
Parametri:
- :id: l’id del dataset da accodare al datset attivo nel caso non sia specificato :driver
- :driver => filename: il nome del driver per leggere il file esterno e il nome del file (vedi File di dati) nel caso non sia specificato :id
- :sheet => sheetname: il nome o il numero del foglio nel caso di un file XLSX
- :mode: definisce l’insieme di variabili del dataset risultante:
- :left o :x: tiene solo le variabili presenti nel dataset attivo
- :right o :y: tiene solo le variabili presenti nel secondo dataset
- :union: tiene tutte le variabili (default)
- :inter[section]: tiene solo le variabili presenti in entrambi i dataset
- :diff[erence]: tiene solo le variabili presenti in uno solo dei due dataset
- :keep => varlist: variabili del dataset che si sta unendo da includere
- :drop => varlist: variabili del dataset che si sta unendo da escludere
- :flag => :varname | [:varname, value] | {:varname => value} flag che identifica i record aggiunti
- :id => :varname | [:varname, start_value | {:varname => start_value}: il nome della variabile con l’identificativo dei record e il valore da cui partire per i nuovi record
Operazioni equivalenti per accodare data2 a data1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # (1)
xlsx.open "data2", :ws => :ds2 # "data2" viene aperto come workspace :ds2 e attivato
spss.open "data1" # "data1" viene aperto e diventa il dataset attivo (workspace di default, 0)
union :ds2 # :ds2 viene accodato al dataset attivo ("data1")
# (2)
spss.open "data1" # "data1" viene aperto e diventa il dataset attivo (workspace di default, 0)
xlsx.open "data2", :ws => :ds2, :bk => true # "data2" viene aperto come workspace :ds2 in background (non si attiva)
union :ds2 # :ds2 viene accodato al dataset attivo ("data1")
# (3)
spss.open "data1" # "data1" viene aperto e diventa il dataset attivo (workspace di default, 0)
xlsx.open "data2", :ws => :ds2 # "data2" viene aperto come workspace :ds2 e attivato
ws 0 # si attiva workspace 0
union :ds2 # :ds2 viene accodato al dataset attivo ("data1")
# (4)
spss.open "data1" # "data1" viene aperto e diventa il dataset attivo (workspace di default, 0)
union :spss => "data2" # "data2.sav" viene aperto automaticamente e accodato al dataset attivo ("data1")
# (5)
spss.open "data1" # "data1" viene aperto e diventa il dataset attivo (workspace di default, 0)
union :xlsx => "data2", :sheet => 1 # "data2.xlsx" viene aperto automaticamente e accodato al dataset attivo ("data1")
# (6)
spss.open ["data1", "data2"] # possibile solo se i file sono dello stesso tipo
|
Unisce un file su se stesso (duplica le righe):
1 2 3 4 5 | spss.open "data1"
union # duplica i record del workspace 0
spss.open "data2", :ws => :ds2
union :ds2 # duplica i record del workspace :ds2
|
Attenzione
union ignorerà eventuali filtri attivi
merge¶
merge unisce le variabili di un dataset esterno al dataset attivo.
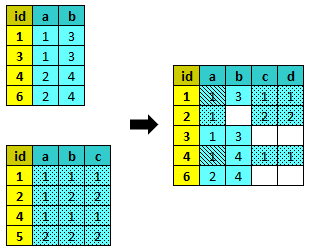
Parametri:
- :id: l’id del dataset da unire al datset attivo nel caso non sia specificato :driver
- :driver => filename: il nome del driver per leggere il file esterno e il nome del file (vedi File di dati) nel caso non sia specificato :id
- :sheet => sheetname: il nome o il numero del foglio nel caso di un file XLSX
- :by => varlist | {x: varlist, y: varlist}: l’elenco delle variabili che compongono la chiave o un hash con gli elenchi per ciascun dataset se i nomi sono differenti. Se omesso, i record verranno uniti sequenzialmente
- :join: i record del dataset risultante:
- :left: tutti i record del dataset attivo (default)
- :right: tutti i record del dataset esterno
- :inner: solo i record che hanno una corrispondenza con il dataset esterno
- :full: sia i record del dataset attivo, sia quelli aggiuntivi del dataset esterno
- :samevar: definisce i comportamento in caso di conflitto con i nomi di variabile:
- :error: genera errore se la variabile da unire è già presente nel dataset attivo (default)
- :skip: ignora eventuali variabili già presenti
- :ren_x: rinomina la variabile del dataset attivo
- :ren_y: rinomina la variabile del dataset che si sta unendo
- :sub: sostituisce completamente la variabile già presente
- :update: aggiorna i dati della variabile già presente
- :upvalid: aggiorna i dati della variabile già presente solo se il nuovo dato è un dato valido
- :upmiss: aggiorna i dati della variabile già presente solo se il dato già presente è un dato mancante (nil)
- :nil => :include|:exclude: include o esclude record con la chiave mancante dalla tabella di lookup (default :exclude)
- :keep => varlist: variabili del dataset che si sta unendo da includere
- :drop => varlist: variabili del dataset che si sta unendo da escludere
- :after => :varname: sposta le nuove variabili dopo la variabile indicata
- :flag => :varname | [:varname, value] | {:varname => value}: flag che identifica i record che hanno trovato una corrispondenza sulla chiave
- :nr => :varname: progressivo all’interno di ciascuna occorrenza della chiave di merge nel database attivo
- :semi => false|true: non unisce nessuna variabile ma, se specificato :flag, marca i record trovati, altrimenti elimina i record non trovati
- :anti => false|true: non unisce nessuna variabile ma, se specificato :flag, marca i record non trovati, altrimenti elimina i record trovati
- :kdup => :error|:warn|:ignore: comportamento in caso di chiave duplicata nel file esterno (default :error)
- :normalize => actionlist: azioni applicate a chiavi di tipo stringa (default [], vedi xmerge)
1 2 3 | spss.open "comuni", :ws => :comuni
spss.open "data1"
merge :comuni, by: {x: [:id_comune, :id_prov], y: [:codcdc, :codpr]}, samevar: :upvalid, flag: {:updated => 2}
|
Operazioni equivalenti per unire panel a survey1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # (1)
spss.open "panel", :ws => :db # "panel" viene aperto come workspace :db e attivato
spss.open "survey1" # "survey1" viene aperto e diventa il dataset attivo (workspace di default, 0)
merge :db, :by => :id # :db2 viene unito al dataset attivo ("survey1")
# (2)
spss.open "survey1" # "survey1" viene aperto e diventa il dataset attivo (workspace di default, 0)
spss.open "panel", :ws => :db, :bk => true # "panel" viene aperto come workspace :db in background (non si attiva)
merge :db, :by => :id # :db viene unito al dataset attivo ("survey1")
# (3)
spss.open "survey1" # "survey1" viene aperto e diventa il dataset attivo (workspace di default, 0)
merge :spss => "panel", by: => :id # "panel.sav" viene aperto automaticamente e unito al dataset attivo ("survey1")
# (4)
spss.open "survey1" # "survey1" viene aperto e diventa il dataset attivo (workspace di default, 0)
merge :xlsx => "panel", :sheet => 2, by: => :id # "panel.xlsx" viene aperto automaticamente e unito al dataset attivo ("survey1")
|
Attenzione
merge ignorerà eventuali filtri attivi
semi_join¶
semi_join trova i record comuni di entrambi i dataset. Se è stato specificato :flag, marca i record trovati, altrimenti elimina i record non trovati. Equivale a merge con l’opzione :semi => true.
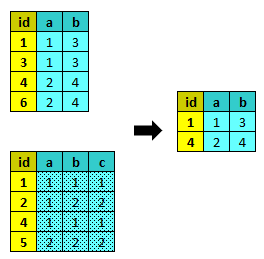
1 2 3 4 5 6 7 8 | # (1)
spss.open "sample1", :ws => :smp1
spss.open "data1"
semi_join :smp1, :by => :id
# (2)
spss.open "data1"
semi_join :spss => "sample1", :by => :id
|
anti_join¶
anti_join trova i record che non esistono nel secondo dataset. Se è stato specificato :flag, marca i record che non esistono nel secondo dataset, altrimenti elimina i record che sono stai trovati anche nel secondo dataset. Equivale a merge con l’opzione :anti => true.
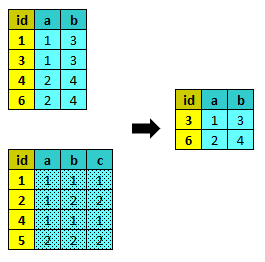
1 2 3 4 5 6 7 8 | # (1)
spss.open "data2"
xlsx.open "sample2", :ws => :smp2, :bk => true
anti_join :smp2, :by => :id
# (2)
spss.open "data2"
anti_join :xlsx => "sample2", :by => :id
|
xmerge¶
xmerge unisce le variabili di un file al dataset attivo in base a una chiave interna e a una o più chiavi esterne che verranno valutate consecutivamente.
E’ usato principalmente per codificare una variabile stringa in base a più varianti del testo.

Parametri:
- :driver => filename: il nome del driver per leggere il file esterno e il nome del file (vedi File di dati)
- :sheet => sheetname: il nome o il numero del foglio nel caso di un file XLSX
- :by => {x: varname, y: varlist}: la variabile della chiave interna e l’elenco delle chiavi esterne
- :code => varanme: il nome della variabile con il codice. Specificarlo solo se numerico
- :label => varname: il nome della variabile da utilizzare per etichettare il codice. Se non specificato, viene usata la prima chiave
- :keep => varlist: l’elenco delle altre variabili del dataset esterno che si vuole includere
- :kdup => :error|:warn|:ignore: comportamento in caso di chiave duplicata nel file esterno (default :error)
- :normalize => actionlist: azioni applicate alle stringhe delle chiavi (default [])
- :strip: elimina gli spazi iniziali e finali
- :squeeze: elimina gli spazi iniziali e finali e gli spazi doppi all’interno della stringa
- :squish: elimina tutti gli spazi dalla stringa
- :case: ignora il maiuscolo/minuscolo nel confronto
- :number: elimina i numeri
- :accent: normalizza le vocali accentate
- :punctuation: elimina caratteri di interpunzione (.,:;!?)
- :special: elimina caratteri speciali (-+@§£$%&^")
1 2 3 4 5 6 | xmerge :xlsx => "comuni", :sheet => "Coding",
:by => {x: :comune, y: [:comu1, :comu2, :comu3]},
:code => :id_comu,
:label => :nome,
:keep => :comu1,
:normalize => [:squeeze, :case, :number, :accent]
|
Attenzione
xmerge ignorerà eventuali filtri attivi
aggregate¶
aggregate riduce i record che hanno la stessa chiave in un unico record applicando le funzioni specificate alle variabili.
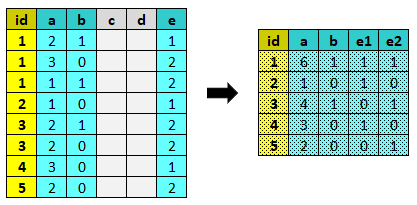
Parametri:
- :key => :varname|[varlist]: un nome di variabile o un array con più nomi di variabili che costituiscono la chiave su cui aggregare i dati. Se omesso tutti i record del dataset verranno aggregati in un unico record. :key è alternativo a :keys.
- :keys => [nil, varname, [varlist]]: un array contenente nil, nomi di variabili e array di nomi di variabili. I dati verranno aggregati su ciascuna delle diverse chiavi (nil per il totale, singole variabili e chiavi multiple) e poi accodati in un unico dataset. :keys è alternativo a :key.
- :mode => :replace|:add:
- :replace: il dataset viene sostituito da quello aggregato (default)
- :add: i dati aggregati vengono uniti ai record esistenti (aggregate+merge)
- :codes => :data|:all|:levels:
- :data: genera solo le combinazioni esistenti delle chiavi (default)
- :all: genera tutte le combinazioni dei codici delle chiavi presenti nei dati
- :levels: aggiunge anche eventuali codici etichettati non presenti nei dati
- :default => value: il valore da inserire nel caso non sia presente nessun record (default: nil, ininfluente con :codes => :data)
- :nr => :varname: progressivo all’interno di ciascuna chiave (solo con :mode=:add)
- :ws => :name: il workspace di destinazione. Se omesso, il nuovo dataset sostituisce quello attivo
- :codes => :data|:all|:levels:
Attenzione
In caso di filtro attivo, aggregate considererà solo i record filtrati
Funzioni di aggregazione¶
aggregate accetta un blocco contenente le funzioni di aggregazione nella forma:
- function newvar => oldvar, options
1) Funzioni che generano una sola variabile.
Il numero delle variabili generate deve essere uguale al numero di variabili di partenza.
- fun :new => :old: applicata a una sola variabile;
- fun [new1, new2, ...] => [:old1, :old2, ...]: applicata a un elenco di variabili.
- :n: il progressivo delle aggregazioni create
- :nval: conteggia il numero di valori validi diversi di una variabile
- :first: il primo valore valido di una variabile
- :last: l’ultimo valore valido di una variabile
- :min: il valore minimo di una variabile
- :max: il valore massimo di una variabile
- :count: (ponderato) senza argomenti conteggia il numero di record che vengono aggregati. Con il nome di una variabile, conteggia il numero di record con un valore valido nella variabile. Con :values considera solo i valori indicati della variabile
- :miss: (ponderato) il numero di valori mancanti di una variabile
- :pct: (ponderato) la percentuale dei valori indicati dal parametro :values
- :avg: (ponderato) la media dei valori validi di una variabile
- :sum: (ponderato) la somma dei valori di una variabile
Le funzioni count e pct accettano anche i parametri:
- :values => []: per limitare i valori da contare, altrimenti verranno utilizzati i valori validi
- :compute => "": permette di specificare un’espressione da applicare ai dati aggregati: utilizzare v# per riferirsi ai valori della variabile
2) Funzioni che generano una variabile a partire da più variabili.
Viene generata una sola variabile a partire da un elenco di più variabili.
L’operazione di aggregazione viene fatta in due diversi passi: prima si effettua un calcolo su ogni record del dataset e poi si aggrega il risultato.
- fun :new => [:old1, :old2, ...]: applicata a una sola lista di variabili;
- fun [:new1, :new2, ...] => [[:old1_1, :old1_2, ...], [:old2_1, :old2_2, ...], ...]: applicata a più liste di variabili.
- :vfirst: seleziona il primo valore valido di un set di variabili e poi il primo valore valido tra i diversi record
- :vlast: seleziona l’ultimo valore valido di un set di variabili e poi l’ultimo valore valido tra i diversi record
- :vmin: calcola il valore minimo di un set di variabili e poi calcola il valore minimo tra i record
- :vmax: calcola il valore massimo di un set di variabili e poi calcola il valore massimo tra i record
- :vcount: (ponderato) conteggia il numero di valori validi in un set di variabili e poi somma il valore ottenuto per ciascun record
- :vmiss: (ponderato) conteggia il numero dei valori mancanti in un set di variabili e poi somma il valore ottenuto per ciascun record
- :vavg: (ponderato) calcola la media dei valori validi di un set di variabili e poi calcola la media del valore ottenuto tra i record
- :vsum: (ponderato) calcola la somma dei valori di un set di variabili e poi calcola la somma dei valori tra i record
La funzione vcount accetta il parametro:
- :values => []: per limitare i valori da contare, altrimenti verranno utilizzati i valori validi
3) Funzioni che generano più variabili.
Vengono generate più variabili a partire da ciascuna variabile.
- fun :new_ => :old: applicata a una sola variabile con nomi generati da una radice
- fun [:new1, new2, ...] => :old: applicata a una sola variabile con nomi delle variabili da generare espliciti
- fun [:new1_, :new2_, ...] => [:old1, :old2, ...]: applicata a più variabili con nomi generati da ciascuna radice;
- fun [[:new1_1, :new1_2, ...], [:new2_1, :new2_2, ...], ...] => [:old1, :old2, ...]: applicata a più variabili con nomi delle variabili da generare espliciti.
- :dummy: crea una variabile per ciascun valore e assegna 1 se la variabile è uguale al valore
- :split: crea una variabile per ciascun valore e assegna il valore se la variabile è uguale al valore
- :counts: (ponderato) crea una variabile per ciascun valore e conteggia il numero di record
- :pcts: (ponderato) crea una variabile per ciascun valore e calcola la percentuale sui casi validi
Queste funzioni accettano i parametri:
- :values => []: per limitare i valori da cosiderate, altrimenti verranno utilizzati tutti i valori etichettati
- :groups => []: per definire delle aggregazioni di valori da cosiderate congiuntamente invece dei singoli valori
- :sep => "": la stringa per separare l’etichetta della variabile da quella dei valori
- :no_varlab => true|false: per non inserire l’etichetta della vecchia variabile nell’etichetta
- :no_vallab => true|false: per non inserire l’etichetta del valore della vecchia variabile nell’etichetta
Tutte le funzioni accettano i parametri:
- :label => "": per definire l’etichetta della variabile
- :levels => {}|false|nil: per definire l’etichette dei valori della variabile
- :default => value: il valore da inserire nel caso non sia presente nessun record (default: nil, ininfluente con :codes => :data)
- :round => value: il numero di decimali a cui arrotondare il risultato)
Le funzioni che prevedono la ponderazione accettano:
- :unweight => true: per ignorare la ponderazione attiva
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | aggregate :key => :id_fam do
count :nrecords, label: "N.RECORDS"
first [:area, :ampc, :regio] => [:mcr, :ampc, :regio]
nval :nvalue_d5 => :d5
sum :totwgt => :peso
avg :meanwgt => :peso
count :msodd_c => :v11, :values => [8, 9, 10]
pct :msodd_p => :v11, :values => [8, 9, 10]
vcount :nlinee => s(:linea_, 1..5)
vsum :toteuro => s(:linea_, 1..5)
vcount :x7 => s(:d7_, 1..10), values: 1
vmax :voto => s(:voto_, 1..10)
dummy :d5_ => :d5, no_varlab: true
split :s5_ => :d5, values: [1, 2, 3, 4], sep: ' '
end
aggregate :key => [:area, :genere], mode: :add, nr: :seq do
count :nrecords, label: "N.RECORDS"
sum :totwgt => :peso
vcount :d7 => s(:d7_, 1..10), values: 1
dummy :d5_ => :d5, no_varlab: true
end
# aggregazioni multiple
aggregate :keys => [nil, :genere, :area, [:genere, :area]] do
count :nr
sum :s1 => :spesa1
avg :a1 => :spesa1, :round => 2
end
aggregate :keys => :area do
pcts [:detr, :pass, :prom] => :v100, :groups => [1..6, 7..8, 9..10], :round => 2
count :nps_c => :v100, :compute => "(v9+v10)-(v1+v2+v3+v4+v5+v6)"
pct :nps_p => :v100, :compute => "(v9+v10)-(v1+v2+v3+v4+v5+v6)", :round => 1
end
|
stack¶
stack genera un nuovo dataset dove i casi sono replicati e differenti set di variabili vengono impilati in una sola variabile per ciascun set originario.
Converte un dataset dal formato wide al formato long.

Parametri:
- :keep => :varname|varlist: (opzionale) una stringa o simbolo oppure un array con le variabili che devono essere riportate come sono nei nuovi record. Se omesso include tutte le variabili tranne quelle che verranno impilate.
- :vars => {}: un hash con i nomi delle nuove variabili e i set di variabili che devono essere impilati:
- :varname => varlist: le chiavi dell’hash sono i nomi delle nuove variabili, mentre i valori sono gli elenchi delle variabili. E’ possibile avere elenchi di variabili con numerosità diverse. Il valore delle variabili mancanti rispetto al numero massimo di gruppi verrà impostato in base al parametro :na.`
- :varnames => [varlist, varlist, ...]: è anche possibile usare come chiave una lista di nomi e come valore una lista di elenchi di variabili.
- :group => {} (opzionale): un hash con la variabile che distingue i gruppi di record. Contiene le chiavi :name, :label e :levels
- :na => value: il valore da inserire per le variabili mancanti (default nil)
- :ws => :name (opzionale): il workspace di destinazione (il dataset viene generato, ma non attivato). Se omesso, il nuovo dataset sostituisce quello attivo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | stack :vars => {:d1 => s(:v1_, 1..10)}
stack :keep => [:ser_no, :area, :genere, :eta, :peso],
:vars => {
:d1 => s(:q1_,1..4),
:d2 => s(:q2_,1..4),
s(:d3_,1..10) => [s(:q3_1_,1..10), s(:q3_2_,1..10), s(:q3_3_,1..10), s(:q3_4_,1..10)],
},
:group => {
:name => :bimestre,
:label => "Trimestri",
:levels => {1 => "Gen-Mar", 2 => "Apr-Giu", 3 => "Lug-Set", 4 => "Ott-Dic"}
},
:ws => :staked
|
In :levels, le forme {1 => "Qt1", 2 => "Qt2", 3 => "Qt3"} e ["Qt1", "Qt2", "Qt3"] sono equivalenti,
ma è necessario utilizzare un hash se si vuole generare dei codici non progressivi: {1 => "Qt1", 5 => "Qt2", 9 => "Qt3"}.
Il numero di gruppi finali è definito dal valore massimo tra i livelli eventualmente specificati in :group e
l’elenco di variabili più numeroso in :vars.
Elencando più livelli rispetto al numero di variabili da impilare si otterranno ulteriori gruppi di record.
Attenzione
In caso di filtro attivo, stack considererà solo i record filtrati
unstack¶
Partendo da un dataset che contiene casi replicati, unstack genera un nuovo dataset contenente un solo record per ogni valore della chiave e affiancando gruppi ripetuti di variabili.
Converte un dataset dal formato long al formato wide.
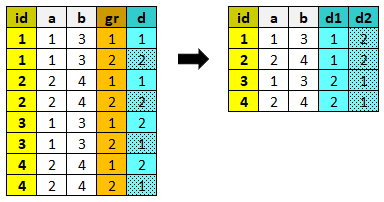
Parametri:
- :key => :varname|varlist: un nome di variabile o un array con un elenco di variabili che identificano i record del nuovo data frame
- :keep => varlist: un array con un elenco di variabili che devono essere riportate come sono nei nuovi record: il loro valore viene assunto come costante rispetto alla chiave; in caso di valori differenti viene tenuto l’ultimo valore
- :group => :varname|{:varname => valuelist}: il nome della variabile che identifica i gruppi da ripetere o oppure un hash con il nome della variabile e l’elenco dei valori dei gruppi da generare
- :vars => varlist: le variabili da ripetere per ciascun gruppo
- :noprefix => false|true (opzionale): se true e :vars contiene una sola variabile, nomina le nuove variabili solo con il valore contenuto nella variabile :group (cioè quando ogni record contiene il valore di una sola variabile e :group il nome della variabile)
- :labelvar => varname (opzionale): quando :vars contiene una sola variabile, cioè quando ogni record contiene il valore di una sola variabile e :group il nome della variabile, labelvar indica la variabile stringa che contiene l’etichetta della variabile
- :labelpos => :start|:end|:none (opzionale): la posizione dell’etichetta dei gruppi all’interno dell’etichetta delle variabili ripetute
- :sep => 'string' (opzionale): i caratteri che separano l’etichetta del gruppo da quella della variabile
- :ws => :name (opzionale): l’ID del workspace di destinazione (il dataset viene generato, ma non attivato). Se omesso, il nuovo dataset sostituisce quello attivo.
Indicando un nome di variabile in :group verranno generati tutti i gruppi presenti nei dati più eventuali altri gruppi presenti delle etichette della variabile, ma non presenti nei dati. Indicando invece un hash con il nome della variabile e l’elenco dei valori, verranno generati solo i gruppi specificati, ignorando eventuali altri valori presenti nei dati e aggiungendo eventuali altri gruppi non presenti nei dati.
1 2 3 4 5 6 7 8 9 10 11 12 13 | unstack :key => :ser_no,
:keep => [:mcr, :genere, :eta, :titolo, :prof, :peso],
:vars => [:v1, :v2, s(:d7, 1..10), :v35, :v47],
:group => :bimestre,
:labelpos => :end,
:sep => " - ",
:ws => :unstacked
unstack :key => [:sample, :ser_no],
:keep => [:mcr, :genere, :eta, :titolo, :prof, :peso],
:vars => [:v1, :v2, s(:d7, 1..10), :v35, :v47],
:group => {:quarter => [4, 5, 6]},
:ws => :unstacked
|
Attenzione
In caso di filtro attivo, unstack considererà solo i record filtrati
vstack¶
vstack genera un nuovo dataset dove i casi sono replicati e i valori di ognuna delle variabili indicate sono impilati generando una variabile
che contiene i nomi delle variabili originarie e una variabile che contiene i valori.
Opzionalmente è possibile inserire anche le label e le informazioni sui formati.
Il tipo di dato della variabile che contiene i valori sarà impostato come il tipo più generico dei dati da inserire.

Parametri:
- :key => :varname|varlist: un nome di variabile o un array con un elenco di variabili che identificano i record del nuovo data frame
- :keep => varlist (opzionale): un array con un elenco di variabili che devono essere riportate come sono nei nuovi record: il loro valore viene assunto come costante rispetto alla chiave; in caso di valori differenti viene tenuto l’ultimo valore (default: tutte eccetto le variabili specificate in :vars)
- :vars => :varname|varlist (opzionale): una stringa o simbolo oppure un array con le variabili che devono essere impilate (default: tutte eccetto le variabili specificate in :keep)
- :variable => varname (opzionale): il nome della variabile che conterrà il nome della variabile impilata (default variable)
- :value => varname (opzionale): il nome della variabile che conterrà il valore della variabile impilata (default value)
- :varlabel => false|true|varname (opzionale): varname il nome della variabile che conterrà l’etichetta della variabile impilata o true assegna le etichette come livelli della variabile (default false)
- :label => false|true|varname (opzionale): varname il nome della variabile che conterrà l’etichetta del valore della variabile impilata o true assegna le etichette come livelli della variabile (default false)
- :info => [vartype, varsize, vardec] (opzionale): i nomi delle variabili che conterranno il tipo, la dimensione e il numero di decimali della variabile impilata
- :ws => :name (opzionale): il workspace di destinazione (il dataset viene generato, ma non attivato). Se omesso, il nuovo dataset sostituisce quello attivo
1 2 3 4 5 6 7 8 9 10 | vstack :vars => [:d1, :d2, :d5, s(:d6_,1..10), s(:d7_,1..10)]
vstack :keep => [:ser_no, :genere, :eta, :etaq, :area, :peso],
:vars => [:d1, :d2, :d5, s(:d6_,1..10), s(:d7_,1..10)]
vstack :keep => [:ser_no, :genere, :eta, :etaq, :area, :peso],
:vars => [:d1, :d2, :d5, s(:d6_,1..10), s(:d7_,1..10)],
:variable => :quastion,
:value => :answer,
:info => [:type, :size, :ndec]
|
Attenzione
In caso di filtro attivo, vstack considererà solo i record filtrati
vunstack¶
Partendo da un dataset che contiene casi replicati con un record per ogni valore di ciascuna variabile e il nome della variabile,
vunstack genera un nuovo dataset contenente un solo record con i valori di ciascuna variabile.
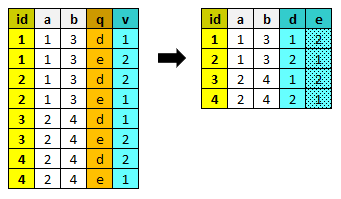
Parametri:
- :keep => :varname|varlist: (opzionale) una stringa o simbolo oppure un array con le variabili che devono essere riportate come sono nei nuovi record. Se omesso include tutte le variabili.
- :vars => :varname|varlist (opzionale): una stringa o simbolo oppure un array con le variabili che devono essere generate
- :variable => varname (opzionale): il nome della variabile che contiene il nome della variabile impilata (default variable)
- :value => varname (opzionale): il nome della variabile che contiene il valore della variabile impilata (default value)
- :varlabel => varname (opzionale): il nome della variabile che contiene l’etichetta della variabile impilata
- :label => varname (opzionale): il nome della variabile che contiene l’etichetta del valore della variabile impilata
- :info => [vartype, varsize, vardec] (opzionale): i nomi delle variabili che contengono il tipo, la dimensione e il numero di decimali della variabile impilata
- :ws => :name (opzionale): il workspace di destinazione (il dataset viene generato, ma non attivato). Se omesso, il nuovo dataset sostituisce quello attivo
1 2 3 4 5 6 7 8 9 10 11 12 | vunstack :key => :ser_no,
:variable => :quastion,
:varlabel => :varlabel,
:value => :answer,
:label => :label
vunstack :key => :ser_no,
:variable => :quastion,
:varlabel => :varlabel,
:value => :answer,
:label => :label,
:info => [:type, :size, :ndec]
|
Attenzione
In caso di filtro attivo, vunstack considererà solo i record filtrati
dupl¶
dupl duplica i record e li accoda al dataset.

Parametri:
- :varname => value: la variabile e il valore che identifica i casi da duplicare
- :id => :varname | [:varname, start_value | {:varname => start_value}: il nome della variabile con l’identificativo dei record e il valore da cui partire per i nuovi record
- :flag => :varname | [:varname, value] | {:varname => value} il nome eo il valore di una variabile per identificare i casi duplicati
1 | dupl :zzz => 1, :id => [:ser_no, 1000], :flag => [:zzz, 2]
|
swap¶
swap scambia i valori delle variabili.

Parametri:
- :varname => value: la variabile e il valore che identifica i casi da trattare
- :by => :varname: esegue l’operazione all’interno delle modalità della variabile
- :groups => [[], []]: i gruppi di variabili
- :seed => number: un seed per replicare i risultati
1 2 3 4 | swap :zzz => 2, :by => :mcr, :seed => 123,
:groups => [ [:a1, :a2, :a3, :b1, :b2, :b3, :b4],
s(:q18_, 1..10),
:x10.to(:z15) ]
|
diff¶
diff confronta due dataset e produce un report con le differenze trovate nella struttura, nelle variabili e nei dati. Può generare una variabile per identificare i record con dati differenti.

Parametri:
- :id1: l’id del primo dataset da confrontare. Se omesso, utilizza il dataset attivo
- :id2: l’id del secondo dataset da confrontare
- :by => varlist | {x: varlist, y: varlist}: l’elenco delle variabili che compongono la chiave o un hash con gli elenchi per ciascun dataset se i nomi sono differenti. Se non specificato, il confronto verrà fatto record per record seguendo l’ordinamento corrente dei dataset
- :keep => varlist: variabili da includere nel confronto
- :drop => varlist: variabili da escludere nel confronto
- :vars => varlist: variabili aggiuntive del primo dataset da listare nel report
- :flag => :varname: flag che identifica i record che hanno dati differenti: verrà assegnato 1 ai record con dati differenti e 2 ai record aggiuntivi (solo se :dat è incluso negli elemnti da confrontare)
- :xlsx => true|false|filename: produce un report in formato XLSX (default true). Può essere fornito un nome di file (senza estensione), altrimenti viene creato automaticamente
- :compare => :all|[:var, :map, :form, :lab, :rec, :dat]: gli elenchi di elementi differenti da produrre (default [:var, :map, :form, :lab]):
- :var: le differenze tra gli insiemi di variabili
- :map|:map##: una mappa dei due set di variabili. Dopo :map è possibile aggiungere la percentuale di corrispondenza tra i nomi delle variabili (default 100)
- :form: le differenze nei formati delle variabili
- :lab: le differenze nelle etichette delle variabili e nei livelli delle variabili
- :rec: le differenze tra gli insiemi di record
- :dat: le differenze nei dati dei record
- :normalize => actionlist: trasformazioni applicate nel confronto delle etichette per il report :lab (default [], vedi xmerge)
- :vardef => false|true: true genera due tabelle con le etichette e i formati delle variabili aggiuntive dei due dataset (default false)
- :match => ##: la percentuale di corrispondenza tra i nomi delle variabili per l’opzione :map (default 100)
La variante xdiff prende come primo parametro il nome del file XLSX. La variante xdiff! apre il file XLSX.
1 2 3 4 5 6 7 8 9 10 | diff :ds1, :ds2, :flag => :diff, :xlsx => "diff"
xdiff "diff", :ds1, :ds2, :flag => :diff
diff :ds1, :ds2, :by => [:id_fam, :id_comp]
diff :ds2, :by => :ser_no, :drop => [:name, :address, :city]
diff :ds1, :ds2, :compare => :map, :match => 65
diff :ds1, :ds2, :compare => :map65
|
diff :ds2, :by => :ser_no, :xlsx => "filediff"
*** Diff: compare dataset <ds1> with dataset <ds2> ***
Datasets
+---------+------------+--------------+
| dataset | n. records | n. variables |
+---------+------------+--------------+
| ds1 | 16 | 10 |
| ds2 | 19 | 9 |
+---------+------------+--------------+
Variables diff
+---------+----+----------------------+
| dataset | n. | additional variables |
+---------+----+----------------------+
| ds1 | 2 | eta, etaq |
| ds2 | 1 | d1 |
+---------+----+----------------------+
Formats diff
+---+---------+--------+-------+-----+-----+-----+-----+-----+-----+----------------------------+----------------+
| # | varname | type | size | ndec | label | levels |
+---+---------+--------+-------+-----+-----+-----+-----+-----+-----+----------------------------+----------------+
| | | ds1 | ds2 | ds1 | ds2 | ds1 | ds2 | ds1 | ds2 | ds1 | ds2 |
+---+---------+--------+-------+-----+-----+-----+-----+-----+-----+----------------------------+----------------+
| 1 | genere | | | | | | | | | 1=>"Maschio", 2=>"Femmina" | 1=>"M", 2=>"F" |
| 2 | area | | | 1 | 2 | | | | | | |
| 3 | d5 | single | float | 1 | 4 | 0 | 1 | | | | |
| 4 | peso | | | | | | | | IPF | | |
+---+---------+--------+-------+-----+-----+-----+-----+-----+-----+----------------------------+----------------+
Records diff
+---------+----+--------+--------------------+
| dataset | n. | by | additional records |
+---------+----+--------+--------------------+
| ds1 | 1 | ser_no | 91 |
| ds2 | 4 | ser_no | 220; 252; 286; 298 |
+---------+----+--------+--------------------+
Data diff
+---+------+--------+-----+-----+-----+-----+-----+-----+----------+---------+
| # | nrec | ser_no | genere | area | d5 | str2 |
+---+------+--------+-----+-----+-----+-----+-----+-----+----------+---------+
| | ds1 | ds1 | ds1 | ds2 | ds1 | ds2 | ds1 | ds2 | ds1 | ds2 |
+---+------+--------+-----+-----+-----+-----+-----+-----+----------+---------+
| 1 | 8 | 9 | | | | | . | 4 | | |
| 2 | 5 | 29 | 1 | 2 | 1 | 4 | | | | |
| 3 | 9 | 56 | | | | | | | AGAZZANO | AGAZANO |
| 4 | 15 | 84 | | | | | 2 | . | | |
| 5 | 12 | 194 | | | | | | | ALTINO | altino |
+---+------+--------+-----+-----+-----+-----+-----+-----+----------+---------+
filediff.xlsx:

pt2diff.bat¶
pt2diff.bat è un utility da linea di comando per confrontare due file di dati. Esegue uno script pTabs2 che utilizza la funzione diff:
Parametri:
- filename1.ext1: il nome (completo di estensione) del primo file di dati da confrontare
- filename2.ext2: il nome (completo di estensione) del secondo file di dati da confrontare
- all: (opzionale) confronta anche il contenuto dei record di dati, se omesso non confronta il conteuto dei record
- outfile: il nome del file XLSX con il report da produrre (default: pt2diff)
1 2 3 4 5 6 7 | pt2diff dati_wave3.sav dati_wave2.sav
pt2diff "dati wave3.sav" "data/w2/dati wave2.sav"
pt2diff dati_wave3.sav dati_wave2.sav report_diff_w3-2
pt2diff dati_wave3.sav dati_wave2.sav all report_diff_w3-2
|